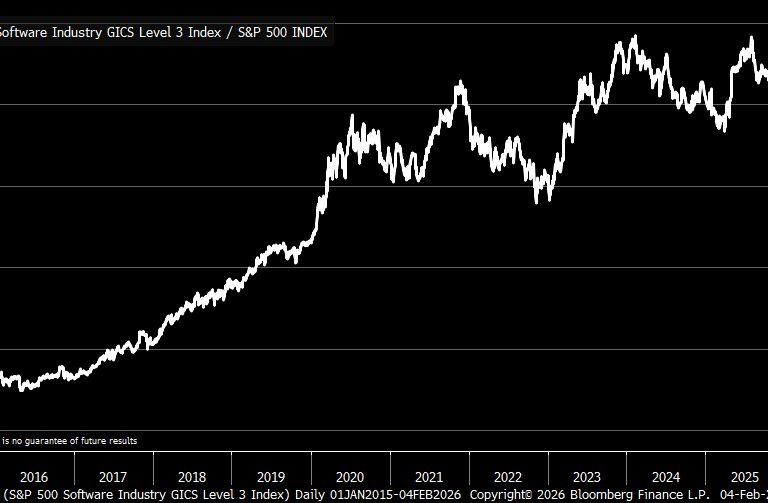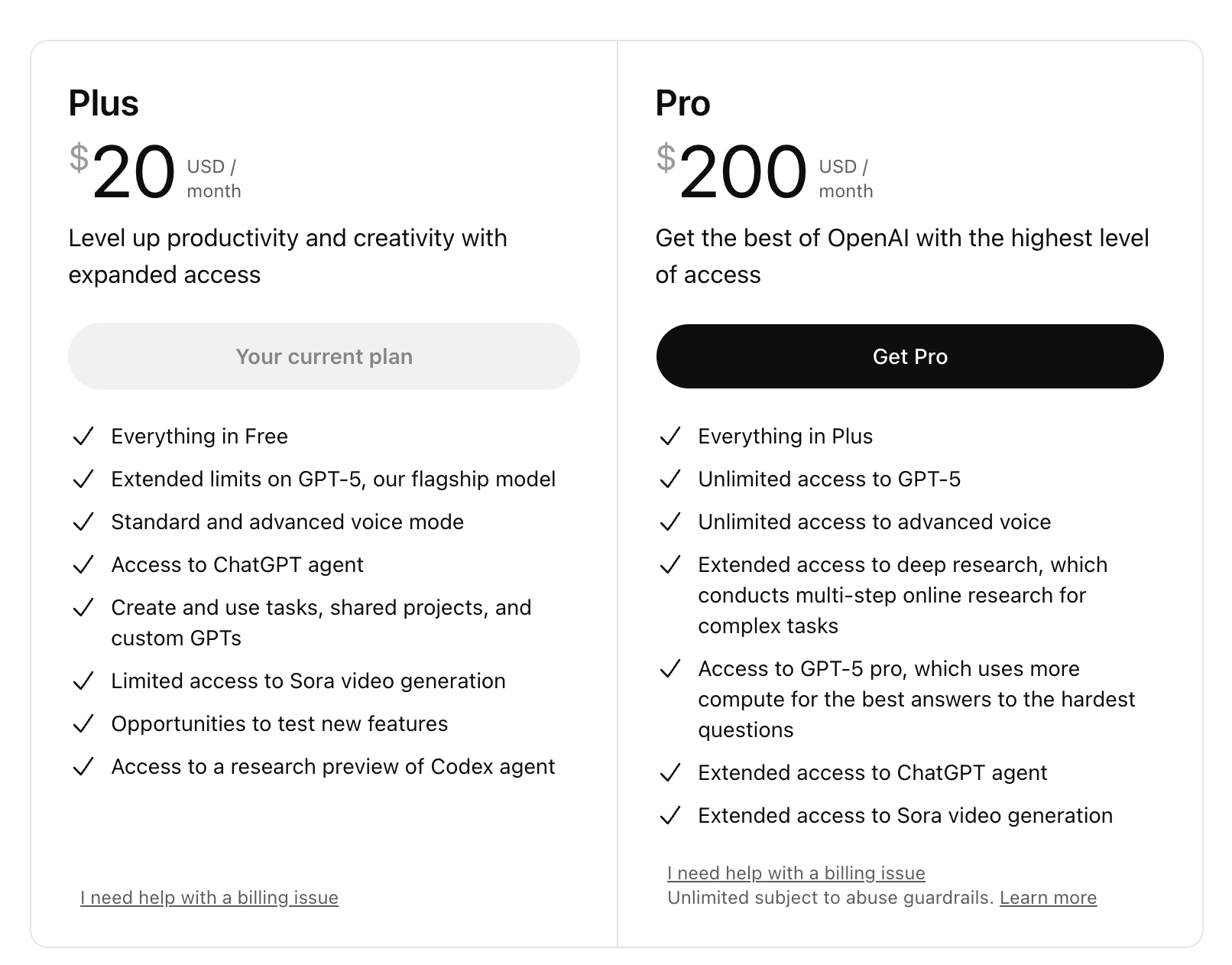
Flat, all-you-can-eat subscriptions don’t map to AI’s cost curve. Every prompt is a variable-cost event tied to tokens, routing, retries, tool calls, and GPU minutes.
That’s why you see eye-popping anecdotes and data points: GitHub Copilot reportedly lost ~$20 per user per month on average (some as high as $80), even at a $10 subscription. Replit’s Agent 3 rollout triggered user bills jumping from ~$100–$250/month to ~$1,000 in days.
Meanwhile, model pricing itself is unmistakably “metered”: Anthropic lists Sonnet 4.5 at ~$3 per million input tokens and ~$15 per million output tokens, with big discounts only if you cache or batch.
Even the “wins” like Claude Code’s rapid adoption are revenue stories with unclear margins unless pricing is compute-aware.
If this trend continues, companies need a proper, compute-aware pricing architecture, one that (1) aligns price with cost-to-serve, (2) aligns price with value delivered, and (3) prevents bill-shock for customers while protecting gross margins for vendors.
Below is a practical menu you can mix-and-match. Pick 2–3 as your core, and use the rest as guardrails.
A. Core pricing models:
1. Pure usage (tokens or GPU-minutes) – preferred & recommended
Charge per million input and output tokens (different rates), or per GPU minute by class (e.g., A100 vs H100 and time slot of the day when used). Add context-length and reasoning multipliers. Publish transparent calculators. (This mirrors how model providers price today)
2. Seat + usage hybrid
A predictable platform fee per seat (covers the app layer, support, and light usage) plus metered overage after an included allowance. Example: $X/seat/month includes 20M input + 5M output tokens; overage billed at posted rates. This stabilizes revenue while keeping heavy users honest.
3. Credit packs with hard caps
Customers prebuy credits (tokens or GPU-minutes). When credits are gone, the product pauses or throttles. Offer auto-top-up with alerts at 50/80/100%. This eliminates “surprise” bills and makes procurement happy.
4. Commit-to-consume (enterprise)
Annual commits for a lower per-unit price, with burst buffers. Think “reserved instances” for AI so that you lock customers in capacity. You get cashflow predictability.
5. Outcome or action-based (for coding/agents)
Charge per accepted PR, test passed, migration completed, or doc processed with capped attempts. Pair with a small base fee + usage floor so you’re not underwriting infinite retries.
B. Value and cost alignment levers
1. Model-class tiers
Price by class: S (fast/small), M (general), L (long-context), R (reasoning/agentic). Route up the stack only when needed; bill accordingly. Make the default S/M to reduce accidental “monster burn”.
2. Quality-of-service (QoS) lanes
Two lanes: Interactive (low-latency) at standard rates, and Batch/Off-peak at steep discounts. Customers choose cost vs speed explicitly.
3. Prompt caching & batch discounts
Offer automatic discounts when cache hits or when jobs are batched. (Anthropic advertises big savings for both; bake that into your pricing so customers see the benefit directly.)
4. Tool-call and retrieval metering
Agentic loops rack up costs. Meter tool calls (web fetch, repo scan, test run) with per-call or per-minute fees, and set max-depth / max-retry defaults. Show these meters in the bill.
5. Context & output multipliers
Long contexts and verbose outputs are expensive. Price larger contexts and streaming completions with small multipliers, nudging efficient usage without nickel-and-diming.
C. Bill-shock prevention & governance
1. Budget envelopes (per user/team/project)
Let admins set daily/weekly/monthly spend caps and token caps. Provide mandatory soft-cap warnings and hard-cap pausing. Moreover, provide real-time burn dashboards at the workspace and job level.
2. Safe defaults
Ship with small-model-first routing, strict retry limits, tool-use opt-ins, and conservative temperature. Expose a one-click “economy mode”.
3. Transparent telemetry
Every invoice line should map to something a human understands: “12.4M input tokens on Sonnet; 3.2M output; 540 tool calls; 6 batch jobs; 31% cached”. That’s how you build trust (and curb support tickets).
4. Risk-sharing SLAs
For enterprise: “If success rate < X% this month, we credit Y% of usage fees”. Pair this with guardrails (attempt caps, human-in-the-loop) so you don’t pay for customers’ unlimited experimentation.
5. Example pricing architectures (mix & match)
- Developer tool (coding assistant)
- $29/seat/mo includes 10M input + 2M output tokens, 5 tool runs/day
- Overage: posted token rates; tool runs at $0.01/run; reasoning tier +50%
- Batch refactors off-peak at 40% discount; PR-merge bounty $0.50/accepted PR (3 attempts max)
- Knowledge worker copilot
- $15/seat/mo includes 5M input + 1M output tokens
- “Review pack” credits: 1,000-page batch review for a flat $12 (slow lane)
- Hard cap by default; admin budgets; live burn meter
- Enterprise platform
- $250k/yr commit for 10B input + 2B output tokens (any mix of S/M/L)
- Additional at public rates; reserved capacity discounts; BYO cloud option (you pay infra, we charge software/license)
- API-only (infrastructure)
- Public, transparent token pricing by model class
- Spot/batch tier with deep discounts; reserved-capacity plan for predictability
- Volume-based rebates post-quarter
D. What “good” looks like?
For vendors: lock in margin with usage-aligned pricing, commitments, and caps. Don’t subsidize infinite experimentation. Meter the expensive parts (context, output, tool loops, reasoning). Publish calculators and surface telemetry so finance teams can forecast.
For customers: insist on live cost dashboards, budget envelopes, and hard caps. Choose lanes (interactive vs batch). Start small-model-first and escalate. You’re not buying “software”, you’re buying compute shaped by software.
AI won’t be sold like Slack. It will look more like cloud: metered, tiered, and commitment-driven because the unit economics demand it. The companies that survive will be the ones whose pricing matches how costs are actually incurred and how value is actually realized, not how SaaS used to be priced. The evidence is already here with loss-leading code copilots, surprise agent bills, and token-based price cards from the model providers themselves.
Selective bibliography:
- Anthropic (2024) Introducing Claude 3.5 Sonnet. 20 June. Available at: https://www.anthropic.com/news/claude-3-5-sonnet (Accessed: 3 October 2025). 
- Anthropic (2025) Pricing — Claude Docs. Available at: https://docs.claude.com/en/docs/about-claude/pricing (Accessed: 1 October 2025). 
- Barr, A. (2025) ‘‘Inference whales’ are eating into AI coding startups’ business model’, Business Insider, 12 August. Available at: https://www.businessinsider.com/inference-whales-threaten-ai-coding-startups-business-model-2025-8 (Accessed: 3 October 2025). 
- Cursor (2025) Clarifying our pricing. 4 July. Available at: https://cursor.com/blog/june-2025-pricing (Accessed: 5 October 2025). 
- GitHub (2024) ‘Enhancing the GitHub Copilot ecosystem with Copilot Extensions, now in public beta’, The GitHub Blog, 17 September. Available at: https://github.blog/news-insights/product-news/enhancing-the-github-copilot-ecosystem-with-copilot-extensions-now-in-public-beta/ (Accessed: 5 October 2025). 
- Replit Team (2025) Introducing Effort-Based Pricing for Replit Agent. 18 June (updated 2 July). Available at: https://blog.replit.com/effort-based-pricing (Accessed: 5 October 2025). 
- The Register (Thomson, I.) (2025) ‘Replit infuriating customers with surprise cost overruns’, The Register, 18 September. Available at: https://www.theregister.com/2025/09/18/replit_agent3_pricing/ (Accessed: 5 October 2025). 
- The Wall Street Journal (2023) ‘Big Tech Struggles to Turn AI Hype Into Profits (AI’s Costly Buildup Could Make Early Products a Hard Sell)’, The Wall Street Journal, 9 October. Available at: https://www.wsj.com/tech/ai/ais-costly-buildup-could-make-early-products-a-hard-sell-bdd29b9f (Accessed: 5 October 2025).